
この記事では、utf-8・Shift JIS・EUCの文字コード判別方法を解説します。
主な文字コード
よく使われる文字コードには、以下のようなものがあります。
UTF-8(ユーティーエフ・エイト)
-
- Unicodeを表現するための可変長文字エンコーディング方式
- 1バイトから4バイトの可変長で文字を表現
- 現在最も広く使用されている文字コード
- Webページやメールのエンコーディングとして標準的に使用
- BOM付きとBOM無しがある
Shift JIS(シフト・ジス)
-
- 日本語のテキストデータを扱うために開発された文字コード
- 1バイトまたは2バイトで文字を表現
- 日本語版Windowsのデフォルト文字コードとして長く使用された
- インターネットの普及以前に日本で広く使用されていた
EUC(Extended Unix Code、イーユーシー)
-
- UnixやLinuxで日本語テキストを扱うために使用された文字コード
- 1バイトから3バイトで文字を表現
- 日本語版のUNIXシステムで主に使用されていた
現在は、多言語対応や国際的な互換性の観点からUTF-8が主流となっています。
ただし、古いシステムやデータでは、Shift JISやEUCが使用されているケースもあるため、 文字コードを正しく認識し、変換することが重要です。
文字コードの確認方法
方法1.テキストエディタで確認する。
OSに標準装備”ではない”テキストエディタを使用することにより文字コードを判別することができます。
以下に代表的なテキストエディタを紹介しますが、これ以外にもほとんどのテキストエディタには文字コードを判別する機能がついています。
【Mac】
【Windows】
※ Notepad++は、正確に判断できない場合があります。
これらのテキストエディタアプリでファイルを開くと、大抵は右下の文字コードが表示されます。
テキストエディタによっては、ここから文字コードを変更することもできます。
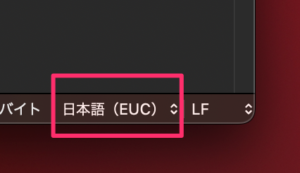
CotEditorの例
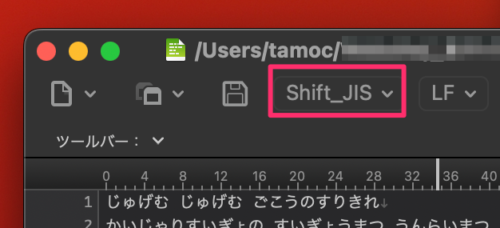
miは、左上に表示される。
方法2.ターミナルで確認する。(Macの場合)
Macの場合、以下のコマンドでファイルの文字コードを調べることができます。
2通りありますが、返す値は違ってきます。
file -I パス/ファイル名
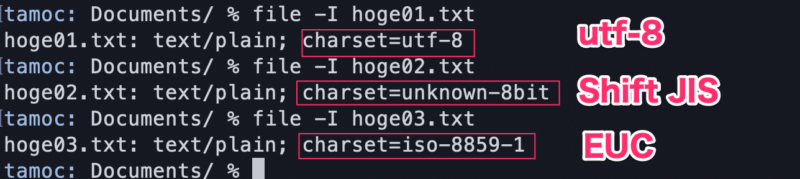
- utf-8 = utf-8
- Shift JIS = unknown-8bit =
- EUC = iso-8859-1
file --mime パス/ファイル名

- utf-8 = UTF-8
- Shift JIS = extended-ASCII text, with LF, NEL line terminator
- EUC = iso-8859
EUC = ISO-8859(やや悟空)




コメント